Try an open demo of Hyphe to build small corpora (crawls are limited to a maximum depth of 1).
Hyphe is easy to install on recent Linux machines (packaged for Ubuntu, Debian and CentOS).
Check our source code on GitHub and feel free to contribute.
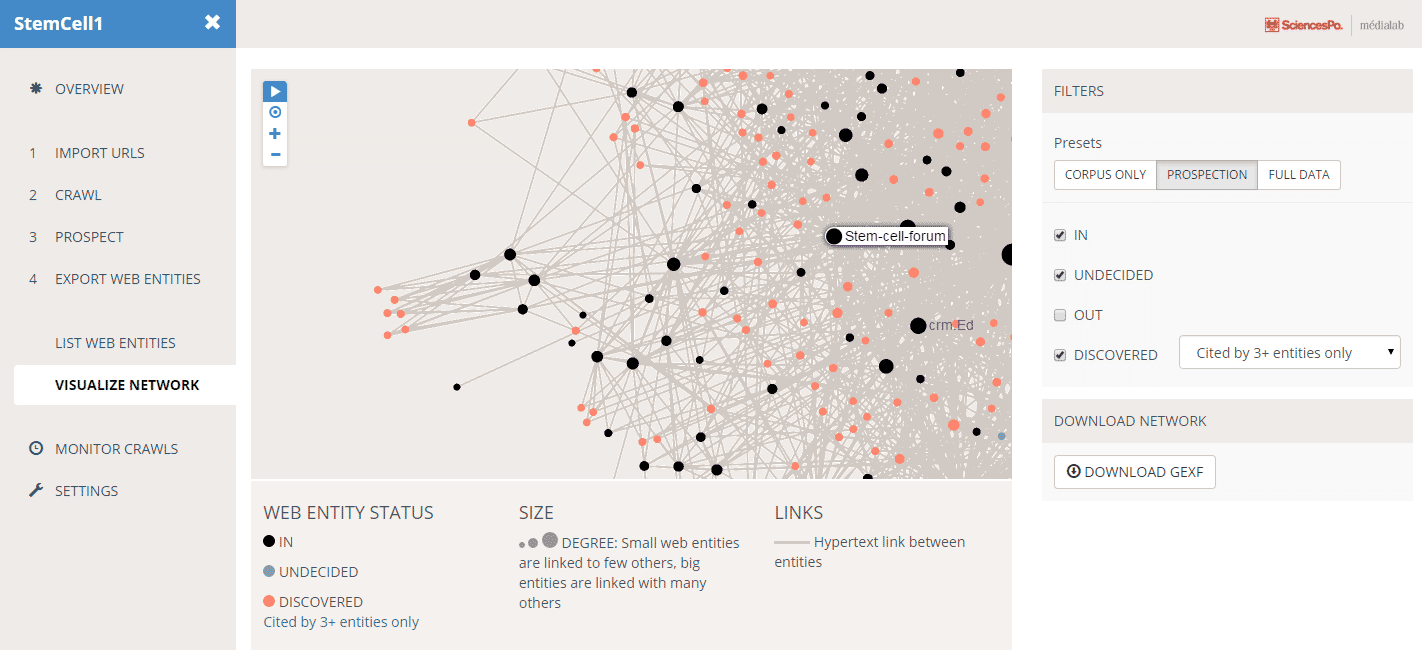
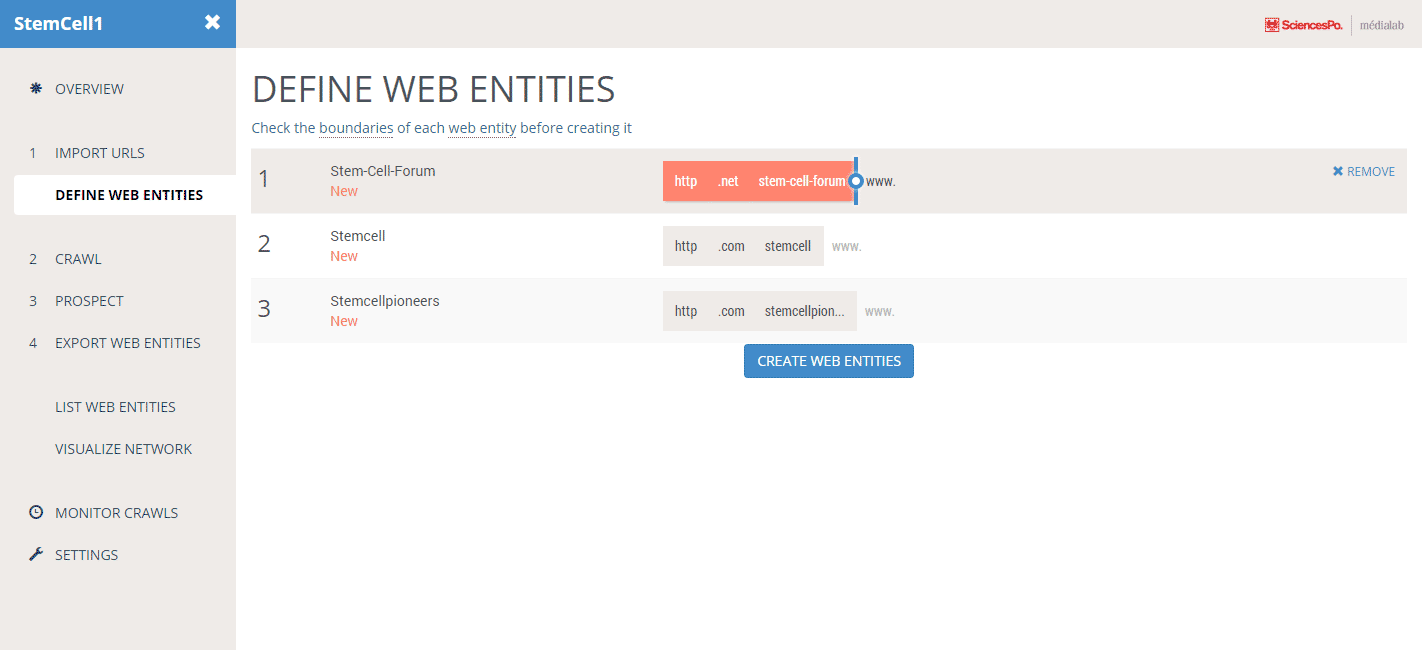
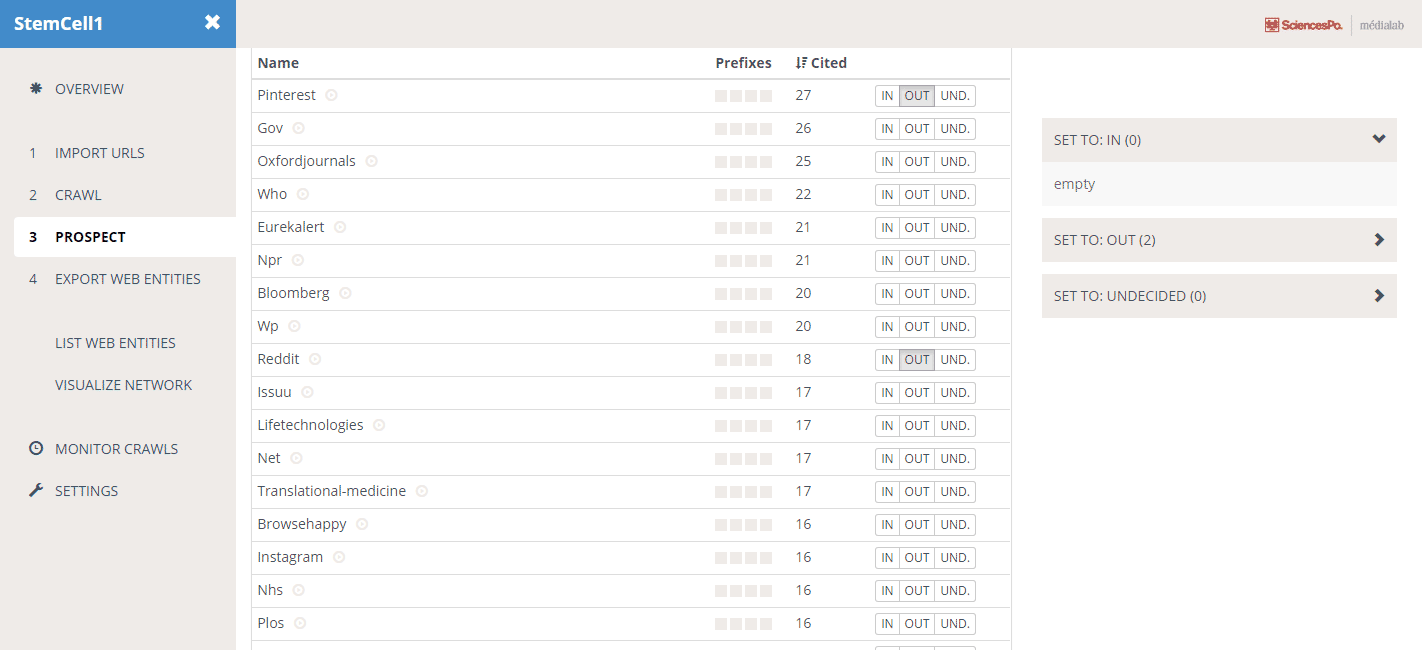
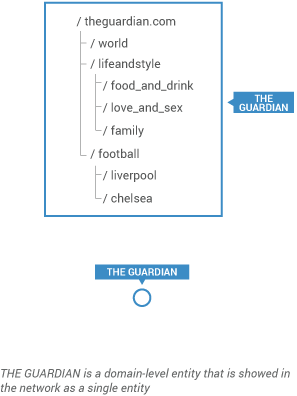
In Hyphe, you choose how web pages are grouped. You can group them by URL: when they share the same domain.tld, or the same subdomain.domain.tld, or the same subdomain.domain.tld/path or …
it’s all up to you
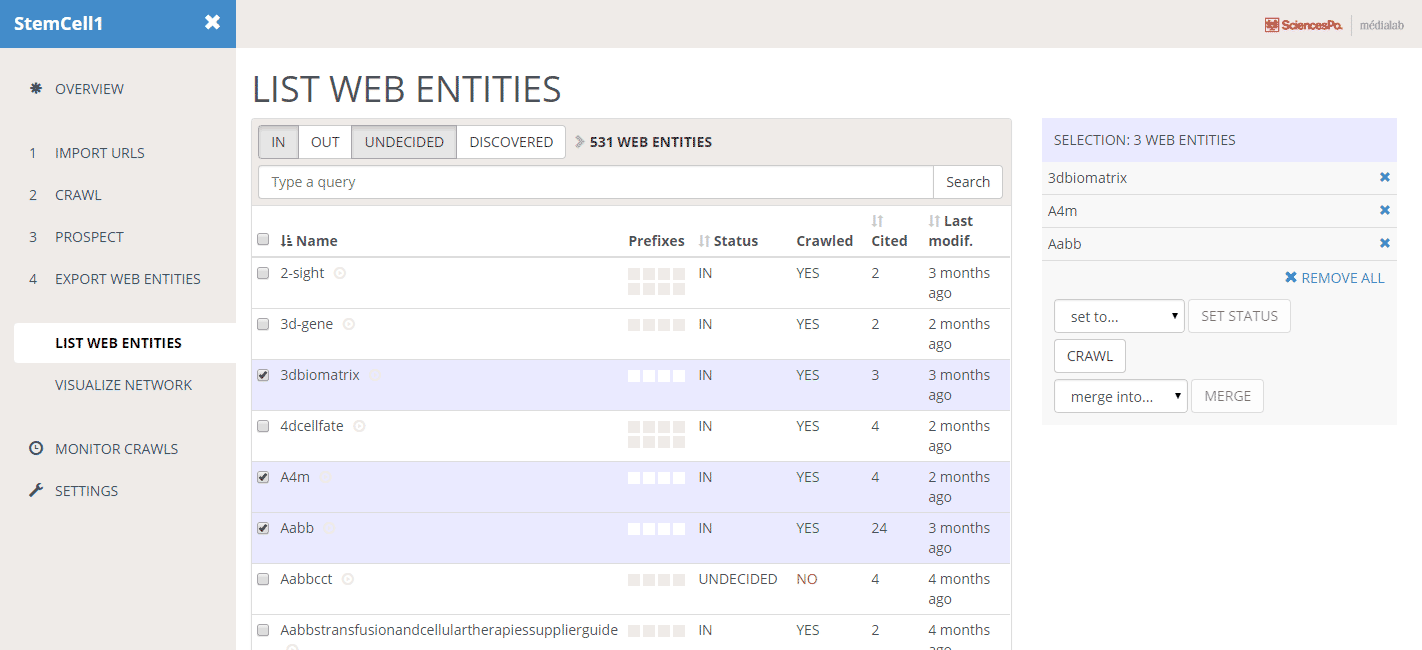
Groups of web pages are called “web entities”. This concept is more flexible and accurate than the intuitive but vague notion of “website”.
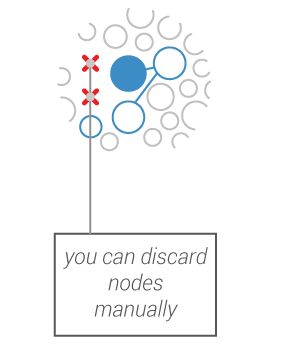
In Hyphe, you decide if a given web entity should be included in or excluded from the corpus: you are a web corpus curator and as such,
you define the boundaries of your own corpus
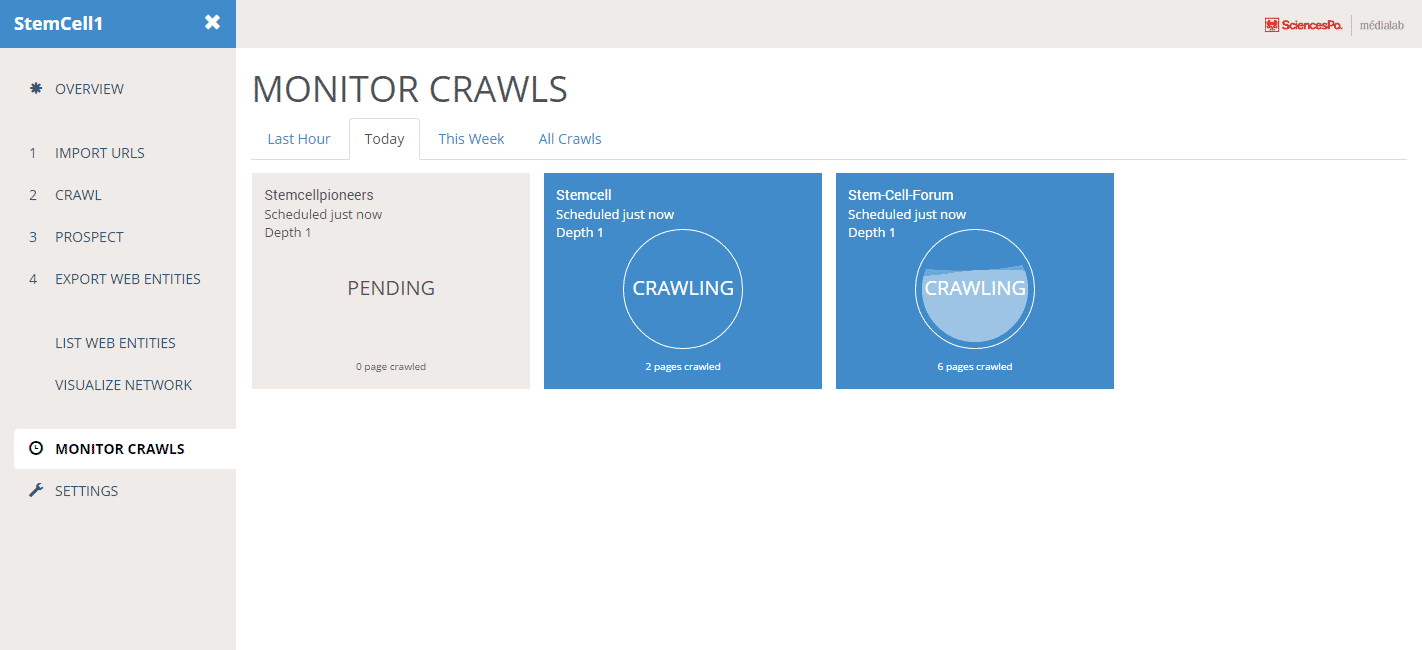
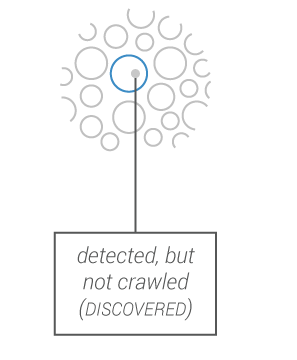
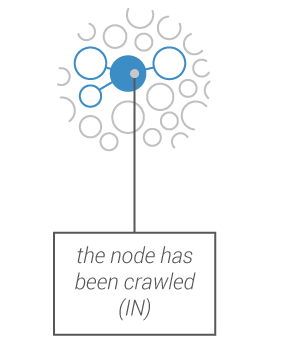
Hyphe uses a web crawler that never harvests anything other than the web entities you specifically targeted. It retrieves internal pages of the target entity (up to a maximum clicks) but never follows outbound links.
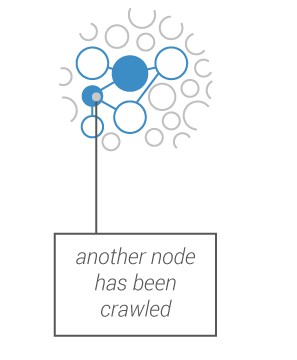
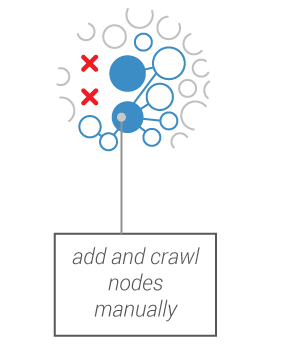
The crawler prospects potential new web entities to be included and you decide what to do with these (include, exclude, crawl…)
This curation activity takes human time, often a lot of time. On a speed vs. quality tradeoff we have invested on quality, having librarians and social scientists as first users.
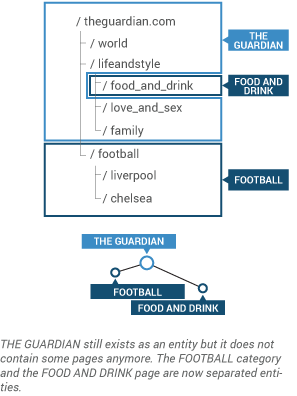
In Hyphe, you can change the definition of a web entity's boundaries at any time. Hyphe features a flexible memory structure which gives you the ability to
change your mind along the way
Hyphe’s memory structure is built on a 3-level data aggregation system.
Crawled web contents are stored as downloaded.
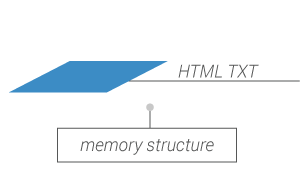
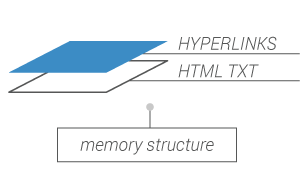
Raw data are indexed at the web page level. Level 1 can be rebuilt from level 0.
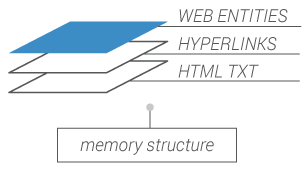
Level 2 is dynamically built from level 1 to provide the network of web entities at any moment.
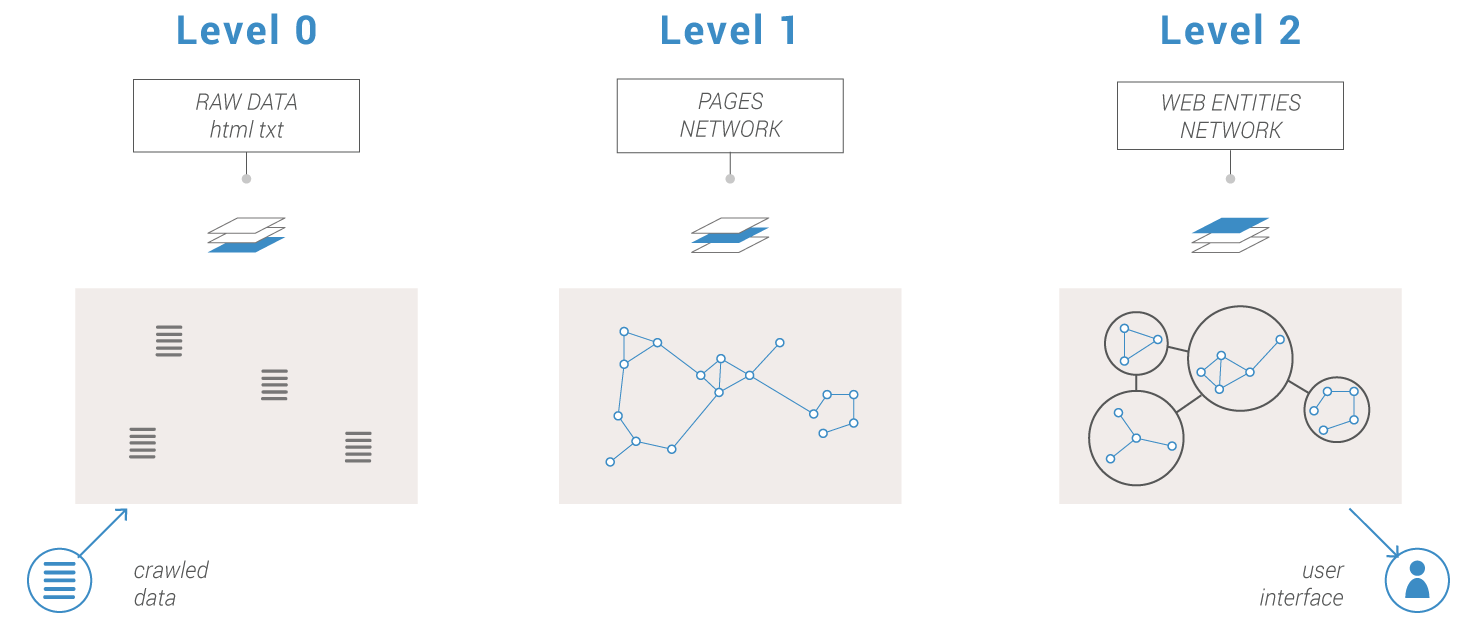
Hyphe behaves nicely with hundreds of thousands crawled web pages (and a billion more detected) grouped in tens of thousands of web entities for a 2 GB RAM and 5 GB filesystem footprint
Share your ideas or issues on:
github.com/medialab/hyphe/issues
Hyphe is a free software under LGPL & CECILL-C licences.
Source code and documentation available on GitHub:
github.com/medialab/hyphe